แบบจาลองอี-อาร์ (Entity-Relationship Model: E-R Model) เป็นแบบจาลองข้อมูล ที่ประยุกต์มาจากแนวคิดเรื่อง Semantic Model และมีการพัฒนามาเป็น E-R Model โดย Peter Pin Shan Chen จาก Massachusetts Institute of Technology ในปี ค.ศ. 1976 และได้รับ ความนิยมมาจนถึงปัจจุบัน
1. ความหมายและความสาคัญของแบบจาลองอี-อาร์
แบบจาลองอี-อาร์ เป็นเครื่องมือที่ใช้ในการออกแบบฐานข้อมูล ที่แสดงความสัมพันธ์ระหว่างเอนทิตีหรือสิ่งที่เราต้องการจะจัดเก็บไว้ในฐานข้อมูล โดยนาเสนอในรูปของของแผนภาพ ที่เรียกว่า อี-อาร์ไดอะแกรม (E-R Diagram) ด้วยการใช้สัญลักษณ์ต่างๆ
แบบจาลองอี-อาร์ มีความสำคัญในการเป็นสื่อกลางเพื่อสื่อสารกับบุคลากรต่างๆ ที่เกี่ยวข้องกับระบบฐานข้อมูล ไม่ว่าจะเป็นในระดับผู้บริหาร นักเขียนโปรแกรม และผู้ใช้ในระดับปฏิบัติการ เป็นต้น ทำให้เข้าใจระบบได้อย่างถูกต้องตรงกัน เนื่องจากมีการแสดงภาพรวม ของระบบในลักษณะของรูปภาพหรือแผนภาพ ทำให้เข้าใจง่าย ดังนั้นระบบที่ออกแบบมาจึงมีความถูกต้องและเป็นไปตามวัตถุประสงค์ขององค์กร
2. องค์ประกอบของแบบจาลองอี-อาร์
แบบจาลองอี-อาร์ ประกอบด้วย เอนทิตี แอตทริบิวต์ คีย์ และความสัมพันธ์ ดังรายละเอียดต่อไปนี้
2.1 เอนทิตี
เอนทิตี (entity) คือ สิ่งต่างๆ ที่ผู้ใช้งานฐานข้อมูลต้องการจะจัดเก็บ ซึ่งมีลักษณะเป็นคeนาม ทั้งรูปธรรมและนามธรรม เช่น บุคคล สถานที่ วัตถุสิ่งของ และเหตุการณ์ต่างๆ เป็นต้น ตัวอย่างของเอนทิตีใน “ระบบการลงทะเบียนเรียนของนักศึกษา” ประกอบด้วย รายวิชา นักศึกษา การลงทะเบียน ผลการเรียนประจำเทอม สาขาวิชา คณะ และโปรแกรมวิชา เป็นต้น
เอนทิตีที่รวบรวมได้จากระบบสามารถแยกแยะและจัดเป็นหมวดหมู่ได้ตามชนิดของเอนทิตี ได้ดังต่อไปนี้
- หมวดบุคคล ได้แก่ เอนทิตี > นักศึกษา พนักงาน ประชาชน ผู้ป่วย และลูกค้า เป็นต้น
- หมวดสถานที่ ได้แก่ เอนทิตี > รัฐ ประเทศ จังหวัด ภาค สาขา และวิทยาเขต เป็นต้น
- หมวดวัตถุ ได้แก่ เอนทิตี > อาคาร เครื่องจักร ผลผลิต หนังสือ วัตถุดิบ และรถยนต์ เป็นต้น
- หมวดเหตุการณ์ ได้แก่ เอนทิตี > การขาย การลงทะเบียน การเดินทาง การสั่งซื้อของ การออกใบเสร็จรับเงิน และการให้รางวัล เป็นต้น
ในอี-อาร์ไดอะแกรม ใช้สัญลักษณ์รูปสี่เหลี่ยมผืนผ้า แทนหนึ่งเอนทิตี โดยใช้ชื่อของเอนทิตีนั้นๆ กำกับอยู่ภายใน เช่น
นักศึกษา แทน เอนทิตีนักศึกษา
2.2 แอตทริบิวต์
แอตทริบิวต์ (attribute) คือ คุณสมบัติต่างๆ ของเอนทิตีที่เราต้องการจัดเก็บในฐานข้อมูล ตัวอย่าง เช่น
- เอนทิตีบัตรประชาชน ประกอบด้วยแอตทริบิวต์ หรือสิ่งที่บ่งบอกคุณสมบัติของประชาชนแต่ละคน ได้แก่ หมายเลขบัตรประชาชน ชื่อ นามสกุล วันเดือนปีเกิด ภูมิลำเนา วันที่ออกบัตร วันที่บัตรหมดอายุ ส่วนสูง น้าหนัก และกรุ๊ปเลือด เป็นต้น
- เอนทิตีพนักงาน ประกอบด้วยแอตทริบิวต์ ได้แก่ รหัสพนักงาน ชื่อ นามสกุล ที่อยู่ เบอร์โทรศัพท์ สถานภาพสมรส และเงินเดือน เป็นต้น
- เอนทิตีสินค้า ประกอบด้วยแอตทริบิวต์ ได้แก่ รหัสสินค้า ชื่อสินค้า ราคา และจานวน เป็นต้น
- เอนทิตีนักศึกษา ประกอบด้วยแอตทริบิวต์ ได้แก่ รหัสนักศึกษา ชื่อ นามสกุล เพศ วันเดือนปีเกิด ที่อยู่ และเบอร์โทรศัพท์ เป็นต้น
- เอนทิตีวิชา ประกอบด้วยแอตทริบิวต์ ได้แก่ รหัสวิชา ชื่อวิชา และจานวนหน่วยกิต เป็นต้น
ค่าของข้อมูลในแต่ละแอตทริบิวต์ประกอบกัน เรียกว่า ทูเพิล (tuple) ซึ่งเป็นแถวของข้อมูลในตาราง โดยแต่ละแถวหรือแต่ละทูเพิลจะประกอบด้วยหลายแอตทริบิวต์หรือ หลายคอลัมน์ของข้อมูล จำนวนแถวของข้อมูลในตารางเรียกว่า Cardinality และจำนวน แอตทริบิวต์ทั้งหมดในตารางเรียกว่า Degree อย่างเช่น มี 4 Cardinality 5 Degree
ในอี-อาร์ไดอะแกรม ใช้สัญลักษณ์รูปวงรี แทนหนึ่งแอตทริบิวต์ โดยใช้ชื่อของ แอตทริบิวต์นั้นๆ กำกับอยู่ภายใน เช่น
2.3 คีย์
คีย์ (key) คือ แอตทริบิวต์ที่สามารถใช้บ่งบอกความแตกต่างของแต่ละทูเพิลได้ อาจเป็น แอตทริบิวต์เดี่ยวๆ หรือ กลุ่มของแอตทริบิวต์ก็ได้
ประเภทของคีย์ประกอบด้วย
2.3.1 ซุปเปอร์คีย์ (super key) คือ แอตทริบิวต์หรือกลุ่มของแอตทริบิวต์ ที่สามารถบ่งบอกความแตกต่างของแต่ละทูเพิลได้
จากตารางที่ 1.1 ประกอบไปด้วยซุปเปอร์คีย์ดังต่อไปนี้
- รหัสนักศึกษา
- รหัสนักศึกษา, ชื่อ
- รหัสนักศึกษา, ชื่อ, นามสกุล
- เลขที่บัตรประชาชน
2.3.2 คีย์คู่แข่ง (candidate key) คือ ซุปเปอร์คีย์ที่น้อยที่สุด ที่สามารถบ่งบอกความแตกต่างของแต่ละทูเพิลได้
จากตารางที่ 1.1 ประกอบไปด้วยคีย์คู่แข่งดังต่อไปนี้
– รหัสนักศึกษา
– เลขที่บัตรประชาชน
2.3.3 คีย์หลัก (primary key) คือ คีย์คู่แข่งที่ถูกเลือก เพื่อใช้บ่งบอกความแตกต่างของแต่ละทูเพิล
จากตารางที่ 1.1 คีย์หลัก คือ รหัสนักศึกษา หรือเลขที่บัตรประชาชน อย่างใดอย่างหนึ่ง
คุณสมบัติของคีย์หลัก
1) คีย์หลักซ้ากันไม่ได้
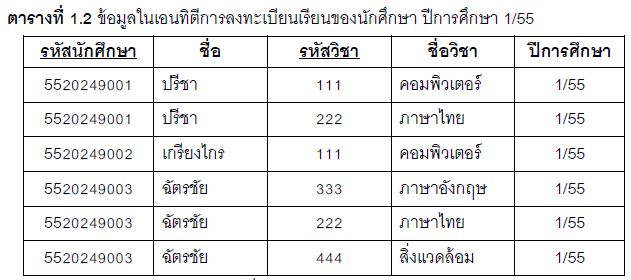
2) คีย์หลักอาจเป็นแค่หนึ่งแอตทริบิวต์หรือกลุ่มของแอตทริบิวต์ก็ได้ อย่างเช่น ในตารางที่ 1.1 มีแอตทริบิวต์เดียวที่เป็นคีย์หลัก ซึ่งอาจจะเป็น “รหัสนักศึกษา” หรือ ”เลขที่บัตรประชาชน” ก็ได้ แต่ข้อมูลบางตารางอาจต้องอาศัยแอตทริบิวต์ตั้งแต่ 2 ตัวขึ้นไปมาประกอบกันเป็นคีย์หลัก เพื่อให้เกิดความแตกต่างระหว่างทูเพิล ดังเช่นในตารางที่ 1.2
จากตารางที่ 1.2 ไม่สามารถให้แอตทริบิวต์รหัสนักศึกษา เป็นคีย์หลักเพียงแอตทริบิวต์เดียวได้ เพราะจะเห็นว่า รหัสนักศึกษา 5520249001 ของทูเพิลหรือแถวที่ 1 จะไปซ้ากับแถวที่ 2 แต่ถ้าให้แอตทริบิวต์ “รหัสนักศึกษา” และ “รหัสวิชา” เป็นคีย์หลัก แล้วพิจารณาข้อมูลของ 2 แอตทริบิวต์นี้ จะเห็นว่าข้อมูลไม่ซ้ากันแล้ว ดังนั้นตารางที่ 1.2 จึงมีคีย์หลักซึ่งประกอบด้วยแอตทริบิวต์ 2 ตัวประกอบกัน คือ “รหัสนักศึกษา” และ “รหัสวิชา”
3) คีย์หลักจะเป็นค่าว่าง (null) ไม่ได้ เพราะฉะนั้นในการกรอกข้อมูลต่างๆ ลงในตาราง แอตทริบิวต์ใดที่เรากาหนดให้เป็นคีย์หลักต้องกรอกข้อมูลให้ครบ คือ จะไม่มีค่าไม่ได้ แต่แอตทริบิวต์อื่นอาจจะปล่อยเว้นว่างไว้ก็ได้ถ้าไม่ทราบค่า
2.3.4 คีย์นอก (foreign key) คือ แอตทริบิวต์ที่ใช้ในการเชื่อมต่อกับเอนทิตี อื่นๆ เพื่อแสดงความสัมพันธ์
คุณสมบัติของคีย์นอก คือ
- คีย์นอกสามารถมีค่าซ้ากันได้
- คีย์นอกสามารถเป็นค่าว่างได้
- คีย์นอกที่ไม่เป็นค่าว่างจะเป็นค่าที่ชี้ไปยังคีย์หลักของเอนทิตีที่สัมพันธ์กัน
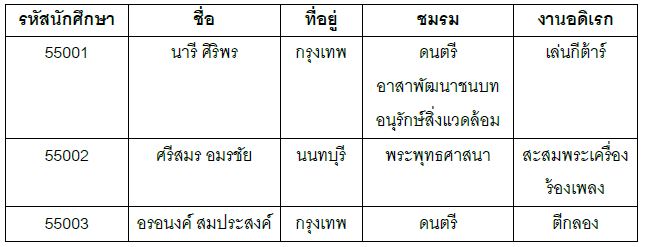
2.3.5 คีย์รอง (secondary key) คือ แอตทริบิวต์ที่ไม่เป็น key หลัก แต่สามารถใช้ในการค้นหาข้อมูลนั้นๆ ได้ โดยคีย์รองจะมีค่าซ้ากันได้ ตัวอย่างเช่น ในตารางที่ 1.3 มีรหัสนักศึกษาเป็นคีย์หลัก แต่หากต้องการค้นหาข้อมูลจากชื่อนักศึกษา แอตทริบิวต์ชื่อก็จะเป็น คีย์รอง หรือถ้าต้องการค้นหาข้อมูลจากนามสกุลนักศึกษา แอตทริบิวต์นามสกุลก็จะเป็น คีย์รอง เป็นต้น
2.4 ความสัมพันธ์
ความสัมพันธ์ (relationship) เป็นการอธิบายความสัมพันธ์ระหว่างเอนทิตีที่มีความความสัมพันธ์กัน ว่ามีความสัมพันธ์กันอย่างไร โดยในอี-อาร์ไดอะแกรมใช้สัญลักษณ์รูปสี่เหลี่ยมข้าวหลามตัด ที่มีชื่อของความสัมพันธ์นั้นกากับอยู่ภายใน และเชื่อมต่อกับเอนทิตีที่เกี่ยวข้องกับความสัมพันธ์ด้วยเส้นตรง ดังตัวอย่างด้านล่าง
ความสัมพันธ์ระหว่างเอนทิตีแบ่งเป็น 3 ประเภท คือ ความสัมพันธ์แบบ หนึ่งต่อหนึ่ง ความสัมพันธ์แบบหนึ่งต่อกลุ่ม และความสัมพันธ์แบบกลุ่มต่อกลุ่ม ดังรายละเอียดต่อไปนี้
2.4.1 ความสัมพันธ์แบบหนึ่งต่อหนึ่ง (one to one relationship หรือ 1:1) หมายถึง ข้อมูลในเอนทิตีหนึ่ง มีความสัมพันธ์กับข้อมูลในอีกหนึ่งเอนทิตีเพียงข้อมูลเดียว ตัวอย่างเช่น นักศึกษาแต่ละคนจะมีสูติบัตรได้เพียงใบเดียวเท่านั้น และสูติบัตรหนึ่งใบก็เป็นของนักศึกษาได้เพียงคนเดียวเท่านั้นเช่นกัน
ในการพิจารณาความสัมพันธ์ระหว่างเอนทิตีแบบหนึ่งต่อหนึ่ง ต้องมองสองทิศ คือ มองจากซ้ายไปขวา และก็ต้องมองจากขวาไปซ้าย แล้วจึงนาความสัมพันธ์ทั้งสองทิศ มาพิจารณารวมกัน ดังภาพที่ 1.6
2.4.2 ความสัมพันธ์แบบหนึ่งต่อกลุ่ม (one to many relationship หรือ 1:M) หมายถึง ข้อมูลในเอนทิตีหนึ่ง มีความสัมพันธ์กับข้อมูลในอีกหนึ่งเอนทิตีมากกว่าหนึ่งข้อมูล ตัวอย่างเช่น ลูกค้าหนึ่งคนมีใบเสร็จได้หลายใบ เนื่องจากลูกค้าหนึ่งคนอาจมาซื้อสินค้าหลายครั้ง แต่ใบเสร็จหนึ่งใบต้องเป็นของลูกค้าเพียงคนเดียวเท่านั้น
ในการพิจารณาความสัมพันธ์ระหว่างเอนทิตีแบบหนึ่งต่อกลุ่ม ต้องมองสองทิศ คือ มองจากซ้ายไปขวา และก็ต้องมองจากขวาไปซ้าย แล้วจึงนาความสัมพันธ์ทั้งสองทิศ มาพิจารณารวมกัน ดังภาพต่อไปนี้
2.4.3 ความสัมพันธ์แบบกลุ่มต่อกลุ่ม (many to many relationship หรือ M:M) หมายถึง ข้อมูลมากกว่า หนึ่งข้อมูลในเอนทิตีหนึ่ง มีความสัมพันธ์กับข้อมูลในอีกหนึ่งเอนทิตีมากกว่าหนึ่งข้อมูล ตัวอย่างเช่น นักศึกษาหนึ่งคนสามารถลงทะเบียนเรียนได้หลายวิชา และวิชาแต่ละวิชามีนักศึกษาลงทะเบียนเรียนได้หลายคน
ในการพิจารณาความสัมพันธ์ระหว่างเอนทิตีแบบกลุ่มต่อกลุ่ม ต้องมองสองทิศ คือ มองจากซ้ายไปขวา และก็ต้องมองจากขวาไปซ้าย แล้วจึงนาความสัมพันธ์ทั้งสองทิศ มาพิจารณารวมกัน ดังภาพต่อไป
3. สัญลักษณ์ในแบบจาลองอี-อาร์
ตัวอย่าง
นักศึกษา และ วิชา เป็นเอนทิตีที่เราสนใจจะจัดเก็บ ซึ่งเอนทิตีนักศึกษาจะประกอบด้วยแอตทริบิวต์ ได้แก่ รหัสนักศึกษา ชื่อนักศึกษา นามสกุล และเบอร์โทรศัพท์ เป็นต้น โดยมีรหัสนักศึกษาเป็นคีย์หลัก ส่วนเอนทิตีวิชาจะประกอบด้วยแอตทริบิวต์ ได้แก่ รหัสวิชา ชื่อวิชา และจานวนหน่วยกิต เป็นต้น โดยมีรหัสวิชาเป็นคีย์หลัก ซึ่งความสัมพันธ์ระหว่างเอนทิตีนักศึกษาและเอนทิตีวิชา เป็นแบบกลุ่มต่อกลุ่ม คือ นักศึกษาหนึ่งคนสามารถลงทะเบียนเรียนได้หลายวิชา และวิชาแต่ละวิชามีนักศึกษาลงทะเบียนเรียนได้หลายคน ดังนั้นเราสามารถนาเสนอในรูปของของแผนภาพ ที่เรียกว่า อี-อาร์ไดอะแกรม (E-R Diagram) ด้วยการใช้สัญลักษณ์ต่างๆ ดังนี้
4. การแปลงแบบจาลองอี-อาร์เป็นโครงสร้างตารางฐานข้อมูล
ขั้นตอนในการแปลงแบบจาลองอี-อาร์เป็นโครงสร้างของตารางในฐานข้อมูล มีขั้นตอนดังต่อไปนี้
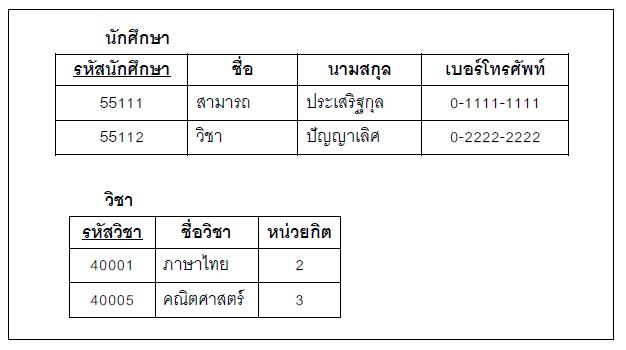
4.1 แปลงเอนทิตีปกติในแบบจาลองอี-อาร์เป็น 1 ตาราง ซึ่งประกอบด้วยแอตทริบิวต์ของเอนทิตีนั้นๆ โดยชื่อของตารางก็คือชื่อของเอนทิตี และแอตทริบิวต์ของเอนทิตี ก็คือ แอตทริบิวต์ของตาราง สำหรับแอตทริบิวต์ที่เป็นคีย์หลักของตาราง ให้ขีดเส้นใต้ที่แอตทริบิวต์นั้น เช่นเดียวกับในแบบจาลองอี-อาร์ ซึ่งจากภาพข้างต้น นำมาแปลงเป็นตารางได้ 2 ตาราง คือ
4.2 แปลงความสัมพันธ์เป็นตาราง
4.2.1 แปลงความสัมพันธ์แบบ 1 : M นั้นไม่ต้องสร้างตารางใหม่ แต่ให้นำแอตทริบิวต์ ที่เป็นคีย์หลักของเอนทิตีที่อยู่ด้านความสัมพันธ์ที่เป็น 1 ไปเพิ่มเป็นแอตทริบิวต์ของตารางด้านที่มีความสัมพันธ์เป็น M
4.2.2 แปลงความสัมพันธ์แบบ M : M จะได้ตารางใหม่ 1 ตาราง ซึ่งประกอบด้วยแอตทริบิวต์ของความสัมพันธ์นั้นรวมกับแอตทริบิวต์ที่เป็นคีย์หลักของ 2 เอนทิตีที่มีความสัมพันธ์ แบบ M : M
จากแบบจาลองอี-อาร์ในภาพที่ 1.11 สามารถสร้างตารางตามขั้นตอนนี้ได้อีก 1 ตาราง คือ ตารางการลงทะเบียน ซึ่งประกอบด้วยแอตทริบิวต์ รหัสนักศึกษา (คีย์หลักของ เอนทิตีนักศึกษา) และ รหัสวิชา (คีย์หลักของเอนทิตีวิชา) ฉะนั้นตารางใหม่ที่เกิดขึ้น ซึ่งก็คือ ตารางการลงทะเบียน มี รหัสนักศึกษาและรหัสวิชา เป็นคีย์หลัก ดังนี้
จากการแปลงแบบจาลองอี-อาร์ตามขั้นตอนข้างต้น สรุปตารางที่ได้ทั้งหมด 3 ตาราง ดังต่อไปนี้
ทั้งนี้โครงสร้างฐานข้อมูลที่ได้จากการแปลงแบบจาลองอี-อาร์นั้นจะอยู่ใน 1NF ดังนั้นจึงจำเป็นต้องนำมำทานอร์มัลไลเซชันต่อ เพื่อให้ได้ฐานข้อมูลที่ปราศจากความซ้าซ้อนหรือซ้าซ้อนน้อยที่สุด แต่ถ้าได้ทำการออกแบบฐานข้อมูลโดยการใช้แบบจาลองอี-อาร์ มาอย่างถูกต้องแล้ว เมื่อแปลงเป็นโครงสร้างฐานข้อมูลแบบสัมพันธ์ จะได้โครงสร้างความสัมพันธ์ที่จัดกลุ่มของแอตทริบิวต์มาเป็นอย่างดี และบางทีโครงสร้างของความสัมพันธ์ที่ได้นั้นอาจอยู่ในนอร์มัลฟอร์มที่สูงกว่านอร์มัลฟอร์มที่ 1 แล้ว อย่างไรก็ตามขั้นตอนถัดมาจาเป็นต้องวิเคราะห์ความสัมพันธ์ระหว่าง แอตทริบิวต์ ซึ่งก็คือ วิธีนอร์มัลไลเซชันที่จะกล่าวต่อไป